
PUBLISHER: Mordor Intelligence | PRODUCT CODE: 2072826

PUBLISHER: Mordor Intelligence | PRODUCT CODE: 2072826
Vocal Biomarkers - Market Share Analysis, Industry Trends & Statistics, Growth Forecasts (2026 - 2031)
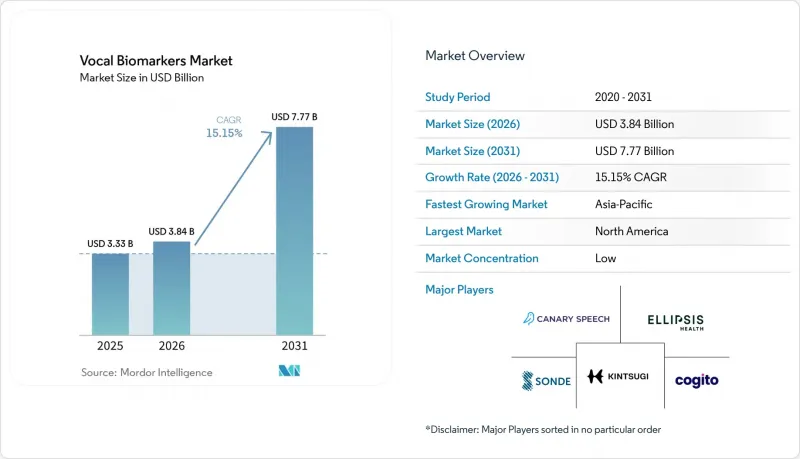
According to Mordor Intelligence, the vocal biomarkers market size is projected to be USD 3.33 billion in 2025, USD 3.84 billion in 2026, and reach USD 7.77 billion by 2031, growing at a CAGR of 15.15% from 2026 to 2031.
This report is Segmented by Technique (Acoustic Features, Prosodic, and More), Platform Type (Cloud-Based Platforms, Web-Based Platforms, and More), Application (Mental Health Monitoring, and More), End User (Hospitals, Pharma and Biotech, and More) and Geography (North America, Europe, Asia-Pacific, and More). The Market Forecasts are Provided in Terms of Value (USD).
Global Vocal Biomarkers Market Trends and Insights
Rising Use of Voice as a Non-Invasive Digital Health Tool
The vocal biomarkers market is thriving, driven by the ability to collect voice data using standard smartphones. This innovation eliminates the need for invasive methods like blood sampling, imaging systems, and wearable sensors. Such ease of deployment is particularly beneficial in rural and underserved areas, where access to healthcare is limited. Research highlighted Sonde Health's vocal biomarker tool, which can assess asthma exacerbation risk using just 6-second vowel recordings. Notably, higher normalized scores indicated a 3.57-fold increased risk of exacerbation in cohorts from both the U.S. and India, spanning five Indian languages. This commercial evidence underscores the vocal biomarkers market's potential to expand into multilingual regions without the need to reconstruct models for each language. Furthermore, there's a noticeable demand in depression screening. The Annals of Family Medicine noted a stark contrast: while routine screening is recommended, only 4% of primary care patients were screened as of 2025. This gap highlights the potential of short-form voice tools in early triage processes.
AI and Machine Learning Improve Signal Extraction Accuracy
The vocal biomarkers market is advancing as model designs evolve, shifting from narrowly defined features to broader representations trained on diverse clinical datasets. In May 2026, the Bridge2AI Consortium unveiled VoiceFM, a dual-encoder model trained on their Voice dataset. This model demonstrated impressive capabilities, including cross-site generalization, Parkinson's detection across English, Spanish, and Mandarin, and multi-condition classification. Another study in 2025 highlighted a hybrid CNN-MLP-RNN model achieving 91.11% accuracy and an AUC of 0.9125 for early Parkinson's detection, utilizing MFCC features with explainability. Such advancements are pivotal for the vocal biomarkers market as clinicians and regulators favor systems that perform well and provide understandable reasoning at the feature level. Vendors with explainable and versatile models are poised for heightened acceptance in hospitals, regulatory circles, and pharmaceutical endpoints.
Limited Clinical Standardization Across Languages and Demographics
Standardization remains a critical challenge for the vocal biomarkers market due to variations in language, recording conditions, and sample design, which affect model reliability. A 2025 review highlighted that compressed audio formats like MP3, M4A, and WMA distort jitter and shimmer, based on an analysis of 17,298 uncompressed voice samples. Another review noted that 94% of 67 machine learning studies on major depressive disorder used fewer than 100 participants, with only 13% addressing varying symptom severity. These gaps hinder the reliable application of published accuracy claims in routine care or global deployment, limiting validation and scalability until larger, harmonized datasets become standard.
Other drivers and restraints analyzed in the detailed report include:
- Remote Patient Monitoring Expands Clinical Utility
- Broader Utility Across Mental Health, Neurology, and Cardiology
- Regulatory Uncertainty for Diagnostic and Monitoring Use Cases
For complete list of drivers and restraints, kindly check the Table Of Contents.
Segment Analysis
In 2025, acoustic feature extraction held a 34.58% share of the vocal biomarkers market by technique, making it the largest segment. This dominance is due to its established use in clinical settings, leveraging parameters like jitter, shimmer, MFCCs, and fundamental frequency. These features remain the foundation for hospitals, research groups, and trial managers, given their integration into earlier algorithms and product development. Prosodic features are significant for affective disorders and Parkinson's-related speech changes, while spectral features are vital for respiratory and cardiovascular assessments.
Hybrid feature models are expected to grow at a 16.52% CAGR through 2031, making them the fastest-growing technique. This growth reflects the need for models that generalize across diseases, languages, and age groups. The industry is likely to retain acoustic features as the operational base while hybrid systems gain commercial traction, despite their more complex validation requirements.
Cloud-based platforms accounted for 67.88% of the vocal biomarkers market in 2025, maintaining their leadership position. Their dominance is driven by the ability to run large models without hardware constraints, update models post-deployment, and integrate with EHR systems via APIs. This architecture aligns with existing data management practices in healthcare and supports centralized model governance.
Cloud-based platforms are projected to grow at a 17.30% CAGR through 2031, remaining the fastest-growing platform type. Embedded SDK and API solutions are also gaining traction, enabling seamless integration into telehealth platforms, call centers, and documentation tools. This dual approach positions cloud platforms as dominant while embedded solutions expand market reach.
Complete Report Scope:
- By Technique
- Acoustic Features
- Prosodic Features
- Spectral Features
- Linguistic Features
- Hybrid Feature Models
- By Platform Type
- Cloud-Based Platforms
- Web-Based Platforms
- Mobile Applications
- Embedded SDK and API Solutions
- By Application
- Mental Health Monitoring
- Neurological Disorder Detection
- Respiratory Condition Monitoring
- Cardiovascular Condition Monitoring
- General Wellness and Preventive Screening
- Clinical Research and Trial Monitoring
- By End User
- Hospitals and Clinics
- Pharmaceutical and Biotechnology Companies
- Contract Research Organizations
- Academic and Research Institutes
- Others
- By Geography
- North America
- United States
- Canada
- Mexico
- Europe
- Germany
- United Kingdom
- France
- Italy
- Spain
- Rest of Europe
- Asia-Pacific
- China
- India
- Japan
- Australia
- South Korea
- Rest of Asia-Pacific
- Middle East and Africa
- GCC
- South Africa
- Rest of Middle East and Africa
- South America
- Brazil
- Argentina
- Rest of South America
- North America
Geography Analysis
In 2025, North America accounted for 38.99% of the global vocal biomarkers market revenue, maintaining its position as the largest regional block. The region benefits from a strong digital health infrastructure, active clinical research networks, and significant pharmaceutical involvement in software-driven endpoint development. The U.S. leads due to clearer regulatory pathways for medical software, despite challenges with uneven reimbursement. Canada contributes through academic and clinical research partnerships, while Mexico, though in early adoption stages, shows potential with telehealth expansion driving wellness and screening-focused voice solutions.
Europe held the second-largest market share in 2025, driven by advancements in hospital digitization and clinical research in Germany, the U.K., and France. The region also influences standards and governance, with initiatives like eVoiceNet promoting unified principles for vocal biomarker development. GDPR regulations, treating voice data as personal information, impose stricter requirements on consent, data usage, and storage, which, while slowing cross-border data exchange, encourage stronger privacy and validation practices.
Asia-Pacific is projected to grow at a 16.64% CAGR through 2031, making it the fastest-growing region. Japan leads with its aging population, high smartphone penetration, and AI-driven elder care initiatives aligning with voice-based monitoring. Studies highlight the value of region-specific models, with Japanese acoustic models achieving an AUC of 0.992 in depression classification. India supports cost-effective multilingual voice data collection, while China progresses with local language standardization, though broader commercialization depends on maturing clinical frameworks. The Middle East, Africa, and South America remain smaller markets, but Brazil is emerging as a hub for Portuguese-language research.
- audEERING GmbH
- Beyond Verbal Communication Ltd.
- Biosensics, Inc.
- Boston Technology Corporation
- Canary Speech, Inc.
- Cogito Corporation
- ConversationHealth Inc.
- Ellipsis Health, Inc.
- EVOCAL Health GmbH
- IBM
- Kintsugi Mindful Wellness, Inc.
- Medical Information Technology
- Noah Labs GmbH
- PST Inc.
- Sharecare, Inc.
- Sonde Health
- VoiceMed Italia S.r.l.
- VoiceSense Ltd.
- Winterlight Labs Inc.
- Zana Technologies GmbH
Additional Benefits:
- The market estimate (ME) sheet in Excel format
- 3 months of analyst support
TABLE OF CONTENTS
1 INTRODUCTION
- 1.1 Study Assumptions and Market Definition
- 1.2 Scope of the Study
2 RESEARCH METHODOLOGY
3 EXECUTIVE SUMMARY
4 MARKET LANDSCAPE
- 4.1 Market Overview
- 4.2 Market Drivers
- 4.2.1 Rising Use of Voice as a Non-Invasive Digital Biomarker
- 4.2.2 AI and Machine Learning Improve Signal Extraction From Short Speech Samples
- 4.2.3 Remote Patient Monitoring Expands Clinical and At-Home Use Cases
- 4.2.4 Broader Utility Across Mental Health, Neurology, Respiratory Care, and Cardiology
- 4.2.5 Integration Into Telehealth, Call Centers, and Enterprise Wellness Programs
- 4.2.6 Growing Research Validation and Clinical Trial Adoption
- 4.3 Market Restraints
- 4.3.1 Limited Clinical Standardization Across Languages, Accents, and Recording Conditions
- 4.3.2 Regulatory Uncertainty for Diagnostic and Monitoring Claims
- 4.3.3 Need for Larger Longitudinal Datasets and External Validation
- 4.3.4 Data Privacy, Consent, and Governance Complexity for Voice Data
- 4.4 Supply/Value Chain Analysis
- 4.5 Regulatory Landscape
- 4.6 Technological Outlook
- 4.7 Porter's Five Forces Analysis
- 4.7.1 Bargaining Power of Buyers
- 4.7.2 Bargaining Power of Suppliers
- 4.7.3 Threat of New Entrants
- 4.7.4 Threat of Substitutes
- 4.7.5 Intensity of Competitive Rivalry
5 MARKET SIZE AND GROWTH FORECASTS (VALUE, USD)
- 5.1 By Technique
- 5.1.1 Acoustic Features
- 5.1.2 Prosodic Features
- 5.1.3 Spectral Features
- 5.1.4 Linguistic Features
- 5.1.5 Hybrid Feature Models
- 5.2 By Platform Type
- 5.2.1 Cloud-Based Platforms
- 5.2.2 Web-Based Platforms
- 5.2.3 Mobile Applications
- 5.2.4 Embedded SDK and API Solutions
- 5.3 By Application
- 5.3.1 Mental Health Monitoring
- 5.3.2 Neurological Disorder Detection
- 5.3.3 Respiratory Condition Monitoring
- 5.3.4 Cardiovascular Condition Monitoring
- 5.3.5 General Wellness and Preventive Screening
- 5.3.6 Clinical Research and Trial Monitoring
- 5.4 By End User
- 5.4.1 Hospitals and Clinics
- 5.4.2 Pharmaceutical and Biotechnology Companies
- 5.4.3 Contract Research Organizations
- 5.4.4 Academic and Research Institutes
- 5.4.5 Others
- 5.5 By Geography
- 5.5.1 North America
- 5.5.1.1 United States
- 5.5.1.2 Canada
- 5.5.1.3 Mexico
- 5.5.2 Europe
- 5.5.2.1 Germany
- 5.5.2.2 United Kingdom
- 5.5.2.3 France
- 5.5.2.4 Italy
- 5.5.2.5 Spain
- 5.5.2.6 Rest of Europe
- 5.5.3 Asia-Pacific
- 5.5.3.1 China
- 5.5.3.2 India
- 5.5.3.3 Japan
- 5.5.3.4 Australia
- 5.5.3.5 South Korea
- 5.5.3.6 Rest of Asia-Pacific
- 5.5.4 Middle East and Africa
- 5.5.4.1 GCC
- 5.5.4.2 South Africa
- 5.5.4.3 Rest of Middle East and Africa
- 5.5.5 South America
- 5.5.5.1 Brazil
- 5.5.5.2 Argentina
- 5.5.5.3 Rest of South America
- 5.5.1 North America
6 COMPETITIVE LANDSCAPE
- 6.1 Market Concentration
- 6.2 Market Share Analysis
- 6.3 Company Profiles (includes Global Level Overview, Market Level Overview, Core Segments, Financials as available, Strategic Information, Market Rank/Share, Products and Services, Recent Developments)
- 6.3.1 audEERING GmbH
- 6.3.2 Beyond Verbal Communication Ltd.
- 6.3.3 Biosensics, Inc.
- 6.3.4 Boston Technology Corporation
- 6.3.5 Canary Speech, Inc.
- 6.3.6 Cogito Corporation
- 6.3.7 ConversationHealth Inc.
- 6.3.8 Ellipsis Health, Inc.
- 6.3.9 EVOCAL Health GmbH
- 6.3.10 IBM Corporation
- 6.3.11 Kintsugi Mindful Wellness, Inc.
- 6.3.12 Medical Information Technology, Inc.
- 6.3.13 Noah Labs GmbH
- 6.3.14 PST Inc.
- 6.3.15 Sharecare, Inc.
- 6.3.16 Sonde Health, Inc.
- 6.3.17 VoiceMed Italia S.r.l.
- 6.3.18 VoiceSense Ltd.
- 6.3.19 Winterlight Labs Inc.
- 6.3.20 Zana Technologies GmbH
7 MARKET OPPORTUNITIES AND FUTURE OUTLOOK
- 7.1 White-Space and Unmet-Need Assessment

